This is a draft...
Most modern computer-use agents (CUAs) are simple extensions of LLMs whose context grows linearly with time.
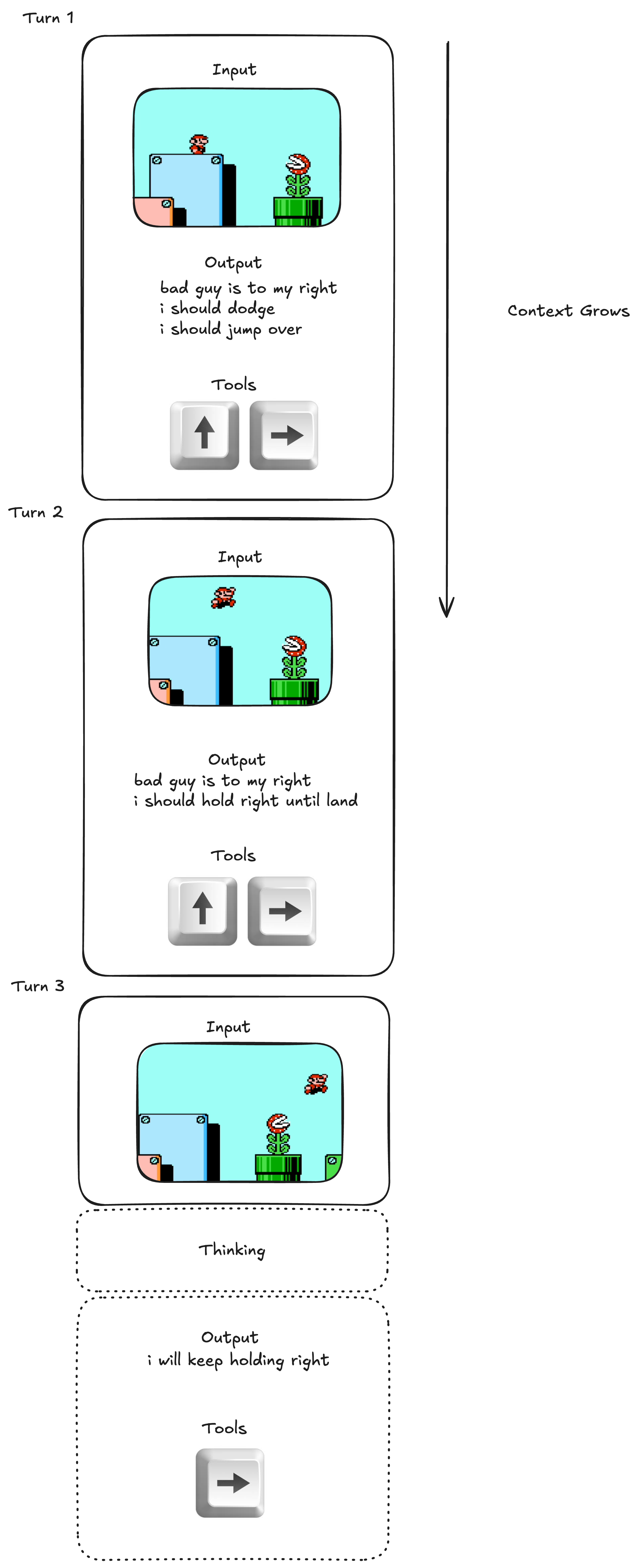
This architecture is fundamentally flawed and will never scale to continuous-time tasks. Even with a 1M context window and running at 1fps (far more detached from reality than any living creature), it can only run for a few minutes before it starts forgetting things. The problem is the conflict between finite context and high frequency feedback.
In this blog, I want to reason from first principles what it actually takes to build a CUA with spatial and temporal intelligence, and then propose a new post-training setup so that LLMs achieve this.
Here's the main result:
- CUAs must do frequent computation.
- To do frequent computation, you must have a fixed-size context window.
Let's break these ideas down.
Idea #1: CUAs must do frequent computation.
Imagine you're playing Mario. What are the thoughts that occupy your mind as you play?
One thing you think of as you play is spatial information, like "the turtle is in the bottom right". Notice that you cannot simply output this statement and be done; in order for this information to be useful, you must constantly update the coordinates of the turtle in your head, once per timestep.
Another thing you might think about is timing, like "the plant will shoot again in .5s". Temporal information like this requires that you constantly tick down the timer in your head.
These computations can be very occupying for human players, which feels like an indication that they're being computed frequently.
Idea #2: To do frequent computation, you must have a fixed-size context window.
A single person, or processor, can only take in a fixed O(1) amount of input per unit time if it's to not slow down. Therefore, if we want to design a continuous-time system, we must give it a fixed-size context window. This contrasts the typical ChatGPT Assistant which takes in O(n) context as time passes.
The Architecture
Putting these ideas together:
Instead of post-training our LLM to output in Assistant-like turns, I propose we post-train it so that it outputs every seconds (fixed, ~ or ). This way Idea #1, frequent computation, is satisfied.
To satisfy Idea #2, we must keep the context window fixed-size. We could do this by truncating the context window when it gets too long, but this would give the LLM very short term memory. The only other option is letting the LLM manage its own memories, either by giving each memory an identifier which it can use to edit, or by having it re-generate all the memories per timestep. I'll assume the latter, and we'll do RL on this so it gets good at it.
Here's a diagram of the architecture:
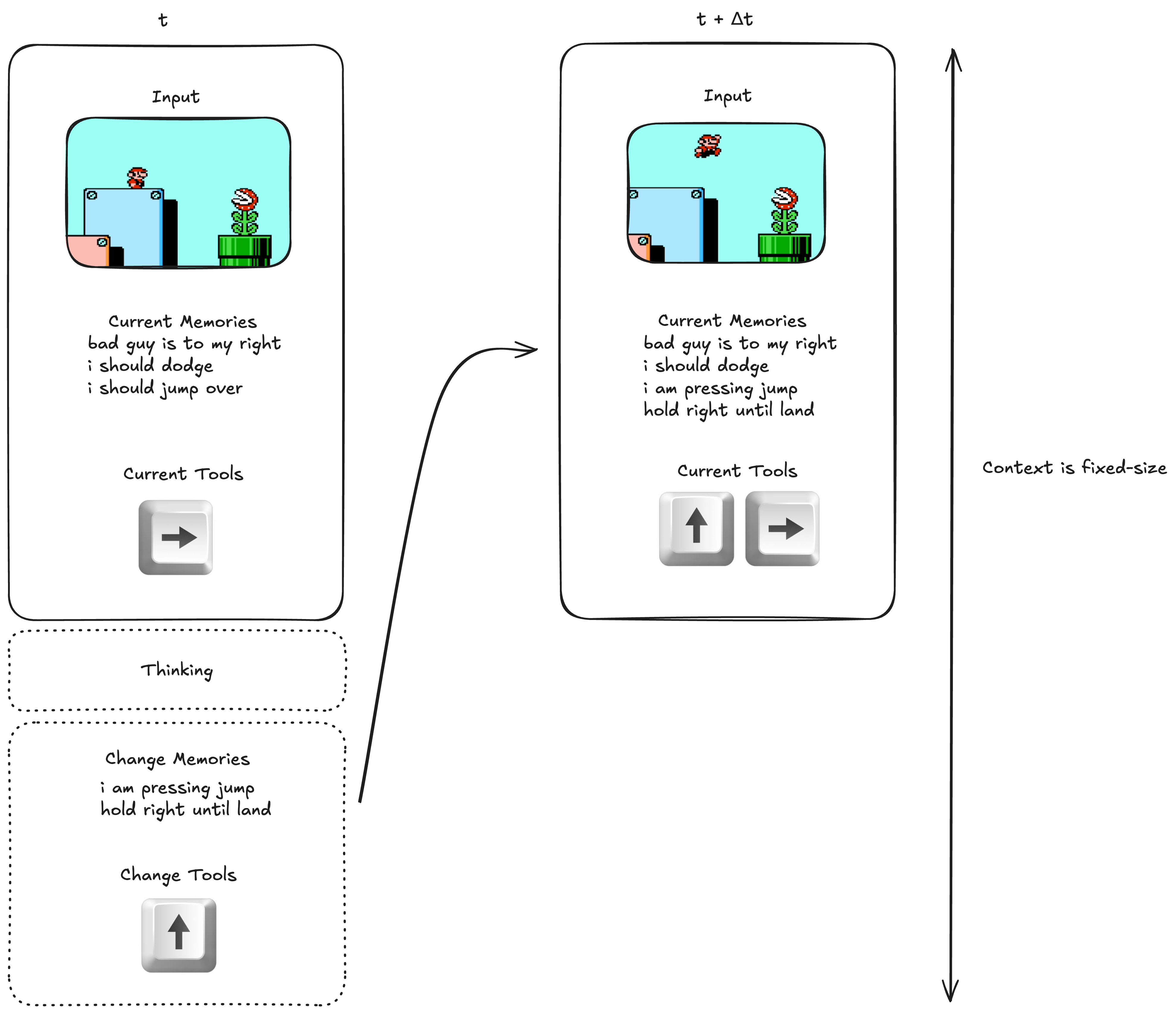
At each timestep, the LLM thinks about what to do, then generates changes to the Tools and Memories. This process is repeated infinitely. Even over many hours of gameplay, the context stays constant1.
Can't we just achieve this with the old architecture? No, the old architecture will forget its past thoughts very quickly at such a small .
Training
To actually build this, we can start with a base model like GPT-OSS and run RL on this architecture to post-train. The base model already understands at a high level what to do in the game, it just needs output tuning.
Standard training. Optimize with GRPO. Sample episodes, and backprop on each generated output in the episode, conditioned on its given input.
Thanks to Mathew Pareles for feedback on this idea.

Footnotes
-
The LLM should learn not to add too many memories, but we can add a hard limit and delete old memories if it goes overboard as a failsafe. ↩